Auteur:
William Ramirez
Date De Création:
20 Septembre 2021
Date De Mise À Jour:
21 Juin 2024

Contenu
Cet article vous montrera comment accéder à la source HTML d'un site Web pour essayer de trouver les informations d'identification. Bien que le code HTML de la plupart des sites Web puisse être consulté dans presque tous les navigateurs, il est probable que vous ne trouviez pas le mot de passe administrateur ou d'autres informations d'identification dans le code HTML, et si vous le faites, un tel site est toujours en construction.
Pas
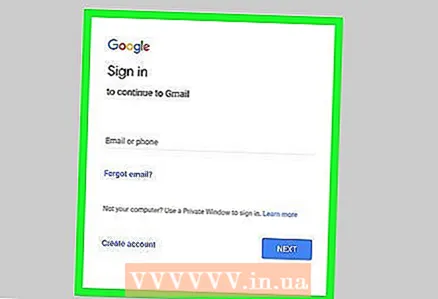 1 N'oubliez pas que cette méthode ne fonctionnera pas pour la plupart des sites Web. Si le code du site Web est hautement sécurisé, les mots de passe et les informations d'identification sont stockés cryptés, ce qui signifie qu'ils ne peuvent pas être trouvés simplement en affichant le code HTML.
1 N'oubliez pas que cette méthode ne fonctionnera pas pour la plupart des sites Web. Si le code du site Web est hautement sécurisé, les mots de passe et les informations d'identification sont stockés cryptés, ce qui signifie qu'ils ne peuvent pas être trouvés simplement en affichant le code HTML.  2 Ouvrez le site Web. Dans un navigateur Web comme Chrome, Firefox ou Safari, accédez au site Web que vous souhaitez pirater.
2 Ouvrez le site Web. Dans un navigateur Web comme Chrome, Firefox ou Safari, accédez au site Web que vous souhaitez pirater.  3 Accédez à la page de connexion. Si le site Web a une page de connexion distincte, cliquez sur Connexion, Connexion ou Connexion.
3 Accédez à la page de connexion. Si le site Web a une page de connexion distincte, cliquez sur Connexion, Connexion ou Connexion. - Si le site est ouvert sur la page de connexion ou que les lignes de saisie des identifiants se trouvent sur la page principale du site, ignorez cette étape.
 4 Ouvrez le code source du site Web. Vos actions dépendent du navigateur, mais dans la plupart des cas, vous pouvez cliquer sur Ctrl+U (Windows) ou Commande+U (Mac). Un nouvel onglet s'ouvrira avec le code source du site Web.
4 Ouvrez le code source du site Web. Vos actions dépendent du navigateur, mais dans la plupart des cas, vous pouvez cliquer sur Ctrl+U (Windows) ou Commande+U (Mac). Un nouvel onglet s'ouvrira avec le code source du site Web. - Dans Microsoft Edge, cliquez sur l'onglet Éléments pour afficher le code HTML.
 5 Ouvrez la barre de recherche. Dans l'onglet source, cliquez sur Ctrl+F (Windows) ou Commande+F (Mac) pour afficher la barre de recherche dans le coin supérieur droit de la fenêtre.
5 Ouvrez la barre de recherche. Dans l'onglet source, cliquez sur Ctrl+F (Windows) ou Commande+F (Mac) pour afficher la barre de recherche dans le coin supérieur droit de la fenêtre.  6 Recherchez les informations d'identification. Dans la barre de recherche, entrez le mot de passe (mot de passe), puis affichez les résultats de la recherche en surbrillance. S'il n'y a pas de mot de passe, entrez un à la fois passer, utilisateur (utilisateur), Nom d'utilisateur (Nom d'utilisateur), connexion (entrée).
6 Recherchez les informations d'identification. Dans la barre de recherche, entrez le mot de passe (mot de passe), puis affichez les résultats de la recherche en surbrillance. S'il n'y a pas de mot de passe, entrez un à la fois passer, utilisateur (utilisateur), Nom d'utilisateur (Nom d'utilisateur), connexion (entrée). - Pour trouver les informations d'identification de l'administrateur du site Web, recherchez le nom d'utilisateur « admin » ou « root ».
 7 Essayez d'entrer un nom d'utilisateur et un mot de passe incorrects. Si vous avez parcouru le code HTML et que vous ne trouvez pas les informations d'identification, procédez comme suit :
7 Essayez d'entrer un nom d'utilisateur et un mot de passe incorrects. Si vous avez parcouru le code HTML et que vous ne trouvez pas les informations d'identification, procédez comme suit : - fermez l'onglet avec le code ;
- entrez des lettres aléatoires dans les chaînes de nom d'utilisateur et de mot de passe ;
- cliquez sur « Se connecter » ;
- rouvrir la page source ; pour cela, cliquez sur Ctrl+U ou alors Commande+U.
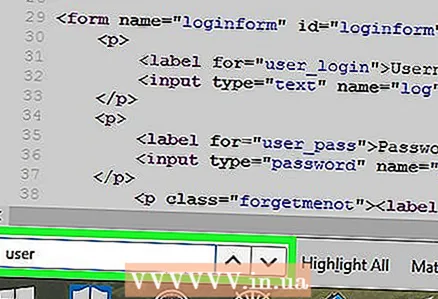 8 Recherchez les informations d'identification. La page source mise à jour affichera des informations sur l'échec d'une tentative d'autorisation ; recherchez maintenant à nouveau les informations d'identification - pour ce faire, entrez les mots-clés indiqués ci-dessus dans la barre de recherche.
8 Recherchez les informations d'identification. La page source mise à jour affichera des informations sur l'échec d'une tentative d'autorisation ; recherchez maintenant à nouveau les informations d'identification - pour ce faire, entrez les mots-clés indiqués ci-dessus dans la barre de recherche.  9 Entrez vos identifiants pour vous connecter au site. Si vous trouvez un nom d'utilisateur et un mot de passe dans le code HTML, essayez de les saisir sur la page d'autorisation du site. Si cela a fonctionné, vous avez trouvé les informations d'identification correctes.
9 Entrez vos identifiants pour vous connecter au site. Si vous trouvez un nom d'utilisateur et un mot de passe dans le code HTML, essayez de les saisir sur la page d'autorisation du site. Si cela a fonctionné, vous avez trouvé les informations d'identification correctes. - N'oubliez pas qu'il est presque impossible de trouver les informations d'identification correctes dans le code HTML de votre site.
Conseils
- Si vous souhaitez pratiquer le piratage de sites, le piratage théorique et pratique peut se faire sur le service Hack This Site. Veuillez noter que vous devez vous inscrire à ce service.
- Connaître les bases du HTML vous donnera un léger avantage lors de la visualisation du code source du site Web de votre choix.
Avertissements
- Le code HTML d'un site Web ne peut pas être modifié dans votre navigateur, sauf si vous avez un accès direct au serveur qui stocke le fichier HTML du site Web.



